Project 52: Weeks 20-22



Due to an interesting fact about how I time these updates, now I have two in the same month. I won’t have another until most of the way though June though. The diet has been going pretty well in May, mostly keeping to the ketogenic diet (essentially very low-carb). The scale is still bugging me on the day-to-day, but I’ve started doing some things which help my outlook directly after the daily weigh-in, so it’s not too bad.
One thing that I really like about the ketogenic diet is that I can eat a lot of meat. I’ve been a meat eater for a very long time now, and I don’t expect to go vegetarian anytime soon. My normal breakfast is made up of eggs and some breakfast meat. For most of April and May it was bacon all the time, but I’ve been mixing it up by switching to some breakfast sausage lately sometimes. I try to make my breakfast a reasonable amount of carbs because I don’t expect to eat throughout the day.
Another nice thing about the ketogenic diet is that on the days when I am not keeping strict count of my calories, or when it is difficult to count the calories because I am going out to eat or something, then I can still stick to my diet without too much fuss. I just avoid all bread, potatoes, sugar, and I guaranteed to keep on the diet. Doing it with both the low-carb and the low-calorie seems to be having an effect, keeping me on my 2 pounds a week goal.
Exercise has been pretty consistent this month, consistently hitting my goals of 5 days a week with taking a day off every 2-3 days normally. One of the nicest things about this time of year is that it is not completely muggy yet, and it also is warm enough to walk around, so I’ve done a couple of nice long walks around the neighborhood. Other than that, I’ve made a habit of watching some educational videos while I’ve been working out, a ton of which are available on youtube thanks to google. Google I/O was last month which means that there are a lot of good talks that I’ve watched that are relevant and recent.
Cheat days have been a little more fast and loose than I have really wanted in this month. My willpower has been a little down lately, and I don’t really know why. It might also be that the progress that I’m making is just making me think that the cheat day schedule isn’t all that important. I took one cheat day on the day of the Doctor Who Meetup, and another on the seventh. The one on the seventh was almost a whole week early, but it made it so that the one on the meetup day lined up so I didn’t care that much.
I feel like I need to plan out my cheat days a little more, becuase twice in the last three times I’ve made the decision to take a cheat day part way through the day - it feels more like my willpower is breaking than I am actually sticking to a diet plan. There are good arguments that I can make in my head for both of these methods of taking the days. On the “planned” side of things, I can feel more like I’m sticking to a plan, and I can plan out the breakfasts as well – pancakes are one of my weaknesses with regards to carbs. On the “unplanned” side of things, I can try to stay off of the carbs for as long as possible, and it is more spontaneous, and if there is a full day where there is nothing to eat but something that includes carbs, I don’t need to starve myself. I’m still not sure what is the best way. I’m going to try this month to stick to the “planned” method a lot more, and see how it goes.
Practice days are making a comeback into my diet, in the form of says where I don’t care that much about carbs, but I still try to make an effort to avoid the big sources - this means no bread or sweets, but I can have maybe one dessert in the day, or maybe I skip all the meals.
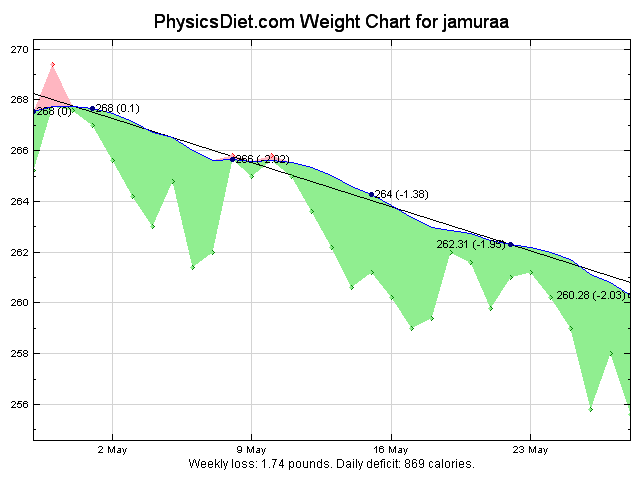
The thirty day graph is looking pretty good, with almost all of the points below the trend line. The beginning of the month and the seventh being the blips above the line because of the cheat days within the month. Interestingly the second cheat day in May didn’t produce an above-the-trendline day at all, although you can kindof see it in the data points. Overall I like seeing this much green in the graph, and the calculated calorie deficit is looking pretty good too.
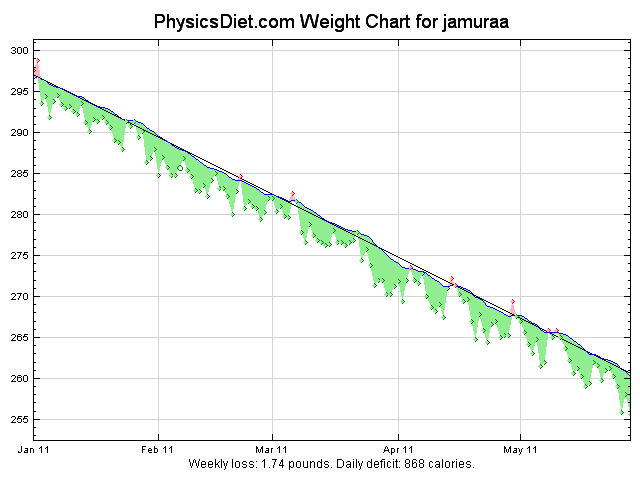
Again the year graph looks pretty awesome. The trend line is looking pretty straight and the overall loss of almost 40 pounds is really great. I haven’t seen any difference in the speed of weight lost between when I was just doing the low calorie diet and the ketogenic diet. It makes me think that maybe the only benefit of the ketogenic diet is adherence.
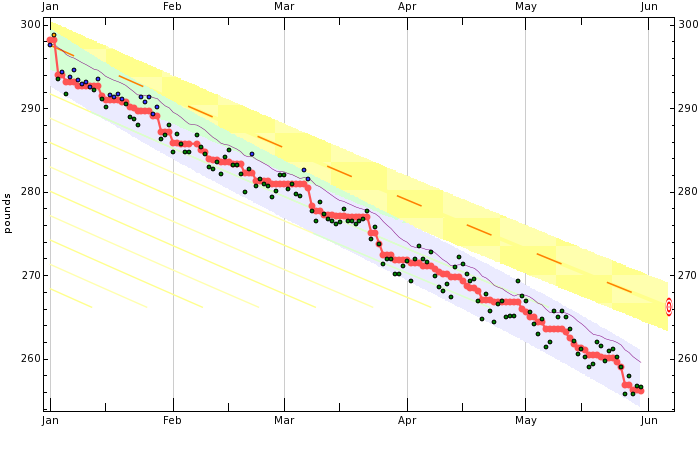
Lately I’ve been using a new service called Beeminder in order to make my daily weigh-in less impactful. I get a graph like this every day, with the trendline similar to the physicsdiet one, but it gets updated every day. Another thing that I like about it is the “yellow brick road”. Mine is set to about 0.5% lost per week, which is the semi-default setting. I have been thinking about changing it to be a little more agressive, but because it’s a beta service you have to email the owner of the site to change your goals. I interact with it by email mostly, and I look at the graph every day as I’m having breakfast and it reminds me that even if I have a more “up” day that I am still below the trend.
I’m getting dangerously close to my short term goal of 250 pounds. I definitely will keep going until I hit 240, because then I will be 100 down. Before and after pictures will come then. At this rate, I will probably be there either at the next checkin or the one after.
Lately at work I’ve been trying to make sure that I follow test driven development. That means that I’m using rspec with factory_girl in order to make building objects to test against easier. As the amount of tests that I have grows, testing gets longer and longer.$
While this gives me a nice break from working, similar to the compile time that a large program used to give me at my old job, usually I want to see the results of my bugfix faster. Turning on rspec test timing had me confused though, because it was saying that the longest test was similar to this one:
describe Product do
it "should have a working factory" do
x = Factory(:product)
x.should be_valid
x.save
x2 = Factory(:product)
x2.should be_valid
end
endThere’s nothing there - it’s all calls to factories that I’ve built. So I went investigating what was actually happening there by making a simple helper for telling me what was actually being built:
def get_model_classes
[].tap do |r|
Dir["# {Rails.root.join("app/models/*.rb")}"].each do |fname|
modelname = fname.split('/')[-1].split('.')[0].camelcase
r << Kernel.const_get(modelname)
end
end
end
# shows a count of all of the relevant objects, to
# determine when we are making too many objects in the world.
def show_object_counts(title = "")
@@all_models ||= get_model_classes
print "Objects in existence: # {title}\n"
@@all_models.each do |k|
if k.respond_to?(:all) then
c = k.all.count
next if c == 0
print " - # {c} # {k}\n"
end
end
endAdding a call after the model factory showed me that I was making
7 User, 5 Address, and about 21 other support objects in order
to simply build a valid Product. There should be ways to eliminate
a large number of those.
A lot of it comes from using x.association :user in the factory.
There are a lot of these in the various factories for this application
because I’m keeping track of who is creating various items.
What I really want to say in most of these places isn’t “I need a
new user that relates to this” but instead “I need a user, any user”
So I’ve started using a construct that follows Model.first or in
these places, so x.association :user becomes
x.user { User.first or Factory(:user) }.
I went to building exactly one User and Address for the whole test suite, and reduced the suite run time from 5m13s to 1m45s by just switching to this wherever I needed an object and not a new one. I’d suggest it to anyone who is having a lot of slow tests and is using factories, it’s saved me at least a couple hours by now considering how often I run tests.
One of the reasons that I’m waking up earlier nowadays is because I can take my commute an hour earlier. I get up at about 4:30, then finish all my prep in an hour, so that I can be on the road by 5:40 at the latest. This means that I’m using the highway much earlier than the rest of the population. There are still a decent number of cars on the road, but it makes the drive easier.
This week I also discovered that it cuts my commute time for the day by at least one third. I woke up an hour later than normal, because for some reason my alarm wasn’t going off that day. I thought I would just do everything an hour later in the day and everything was going good up until I got onto the highway at 6:40. Suddenly there was a lot of traffic on the road, and all of the congestion traffic controls were in effect. It lengthened my commute from a normal 20 minutes to 35, and made me even later than I was in the first place.
An hour later in the morning is 75 minutes. It put my whole day back even farther than normal. I ended up taking an early day because I know that on the other direction it’s also at least 15 minutes more when I have left late because I was busy at work, sometimes it’s even as long as double. Suddenly my day would be 23 hours.
With the amount of time I have, I am making sure for as long as I can that I will be up on time. Of course, the ideal commute might be from the bedroom three steps to the office - at some point I might want to try that once a week. There are other advantages to going into the office though, especially at my work where there is a whole lab of equipment needed sometimes.
This weekend while I was playing around with stuff, I decided to improve an app that I’ve been using on my phone for a while. The app is Tagtime, an application which helps me keep track of the time that I am spending on things by sampling me randomly. I was happy to find it because I was thinking of building an app with a similar purpose (although my approach was not statistical but rigorous) and because it was both simple and open source. There were a couple of things that I wanted to improve about it, and the source is right there on github so I could download it and start making it better. Also github is a “social coding” platform which means that I can make changes to the app and then submit a “pull request”, requesting that the feature that I worked on be included in the main repository. The basic idea is that people will fork (or branch, the terminology is fuzzy) the repository and then make improvements, and if they are good, then they will be included in the “canonical” version of that repository, and be used by more people. This is the way that things like Linux have worked for a while on git, but it was kind of tricky to set it up until github came along and made it easy.
One thing that github encourages on it’s help page on pull requests is that you make a feature branch for your changes, so that it’s easy to update the pull request later, and so that it’s not mixed in with a bunch of other things. This is generally a good idea, but I hadn’t used it in practice until this weekend. I discovered that it’s a little cumbersome when you are doing a lot of little changes like the ones I made.
First, you need to know that you’re actually working on a feature, and not get distracted by some other feature at the time. Git is actually pretty good at this, because if you find that you’re mixing a couple of features together, you can simply not commit some of the files, or even only commit the parts of the files you want. Next you need to actually create the branch of the feature. Thinking up a name for this branch might be important, but it’s not as important as later when you actually initiate the pull request. After that, you do the work on the branch, and then commit your changes to your version of the repository that belongs to you. Finally, you go to the github site and click the pull request button. Then you will fill out a title and description for your pull request (this is the more important part). Hopefully then someone will look at it and integrate it in.
Then you go and work on another feature. But wait, what should your other feature be based on? You have to branch from somewhere in step two. Here’s where feature orthogonality comes in. If your feature doesn’t depend on the one that you just worked on, then you should make another branch from the original fork’s master branch. Hopefully you haven’t actually committed any on your master branch in the meantime, and it’s easy to find.
Maybe an example will help. Originally I branched my repository of TagTime from the original repository. Then I set out to make
my feature reality - that is, cleaning up tags that aren’t in use because they will clutter my screen when I’m tagging (I mistyped them once and now they’re everywhere!).
I created the cleanup-tag-button branch from the master branch and then worked on my changes. I committed them (they weren’t much, just one commit)
and then generated this pull request. Then I wanted to work on another feature - there was a delay in hitting the buttons when it polled
me. I rewound my branch to the master branch again, and then created the speedier-tagging branch from the same spot. These features
were orthogonal, which means that I could do this without an issue, and test the features in isolation. I did the same to update the icon
that is used in the notifications, because it was black-on-black in my UI, adding a white background in the visible-icon branch. You can see
how all three branches sprout from the same commit (the most recent commit on the “canonical” repository) in my network.
There are two actual issues that I found when I was
working with this model. The first actual problem is that when I was working on this, I
wanted to have a copy of the app with all of my new features in it. For this
reason I created the integration branch, so that I could put all of my
features together. This makes it easy to make sure that my features are
orthogonal as well, because if I can’t get integration to work, then they are
conflicting. It’s somewhat annoying to re-merge all of the branches every time
that I update it just to get a new copy. The second actual problem was that I
was stuck working in the branch for each feature when I was working on the feature.
This meant that I couldn’t use some of the changes that I made in the other branches
and I was somewhat lost when I was testing it on my phone when, for example, the
visible icon wasn’t there when I was testing that the speedier tagging worked.
I also thought of two theoretical issues that I didn’t actually run into, but could have imagined running into quickly. The first was the problem of non-orthogonal features - should they just be included in the branch for the feature that they depend on, essentially making them part of that feature, or should I branch again from that feature branch to go one level deeper. What would a pull request for the second feature look like? I ran into this problem because the canonical repository for TagTime has a bunch of files in it that shouldn’t be there, compiled files that I don’t expect in the repository. I would have based my branches off of a cleaned up version of the repository, but I didn’t want to force that choice onto the original branch, so I was working in the “messy” repository for most of the time.
The other
theoretical issue involves publishing, tracking, and rebasing. I would like to say that if the
“canonical” repository master changes, then I could rebase the feature branches against it, but if
I do then I have to push a non-fastforward of that branch to github, and it looks all strange.
If someone had that branch and was forked off of my integration branch for example because
they want all of my features, what would happen when I rebase the feature branch? It’s unclear
to me.
All in all, I was happy with the model. I’m not sure what a better model would be - maybe there is something in darcs or mercurial that would be better for this type of collaboration and wouldn’t have the issues of above. In the meantime, I’m going to keep trying to keep my features orthogonal and work with a feature branch model.

Last weekend I did something which many people who might know me would think I am completely opposed to, yet I do almost once every two months nowadays. I visited the casino. Visiting the casino isn’t strange on it’s own, but I didn’t go to see a show or have the buffet (although I did partake in the buffet this time), but to gamble my money away.
Usually the games at the casino are set up so that the house always wins. I know that in my mind, and my only hopes on most of the trips there are to spend as much time as possible having fun while losing the least amount of money. Lots of people go there and play poker, which is not actually played against the house (although usually there is a fee paid to the house to play) and they have a lot of fun and make money doing it. Alternatively they’ll play blackjack, which theoretically could be actually slightly on the player’s side if they played perfectly and were allowed to count all the cards.
I play something which is much more in the casino’s favor though - I play slots. The variety of games peaks my interest and I love that I could play each different type for five minutes and never repeat playing the same game twice. They are obviously a big money maker for the casino - they are all over the place, covering almost every square inch of floor which isn’t needed for walking or the gaming tables. The only thing that I can think which gets more space is the BINGO hall.
I find two things fascinating about slot machines. The first is that they are basically a rudimentary video game where you can win money. You put your money in, you push the button and you either get more money out, or you lost your money. This is the essence of gambling, without any of the facade that is messing around with cards or playing with numbers. Slots take your money and show you some flashy lights and then they give you the result. It’s part of the reason that the casinos like them so much - they have a fast result.
The second reason is that I am fascinated by the math which must be involved with the slots. They are only ever so slightly in the favor of the casino, although they always are, but they have to make it seem like it’s possible to win them. The variations on the reels and the combinations for winning the game which is presented are nice to think about. There are a lot of different types of slot games, some of which will give you free games every once in a while, some have wild cards, some have more or less symbols, or symbols in a different order. Also there are many different combinations of winning lines, making it “easier” for you to win a prize on wheels which don’t actually line up exactly. The math which must go into the more complicated ones I’m sure is quite complex to prove that yes, indeed, the game is tilted toward the house even when you play with all of the varied ways to win and the bonus games or free spins which show up.
Many would say that it’s a tax for people who are bad at math, but I like to think of it as the math factory. You build these games that will return value to you because the math says so. Sometimes it doesn’t work out in the short term, but the math factory will always create it’s value in the end, just like the factory that produces milk or widgets.
Diana likes to go and play the video poker, which I actually like to play as well, but I’m not as lucky as her. I’ve been thinking of playing around with some of the math involved, and see if I can figure out some of the games and how exactly they work. They’re not exactly opaque but not really transparent either. I might have to take some trips to the factory floor for some research.
I’m always looking for a better way to get things done, and keep track of what I need to get done. In the past I’ve used a lot of systems to handle the parts of capturing and completing tasks. I started first with reading a lot of blogs and getting hooked on some systems like the Hipster PDA which was what I tried for a while. I then moved along to something else using a Moleskine notebook, and then shortly for a while using a set of cards which I had written down things on and carried around with me at all times. I switched whenever a system seemed to stop working or just have a big enough backlog pile so as to make it obvious that it is not working for me to actually get the things completed.
I think that there are a few things about a todo system which are important. Ubiquitous capture is very important. That means that it must be available at all times, and the easiest way to do that is to make it paper-based. I have a smart phone with me almost all time so it might be acceptable for a todo system to use that, but I definitely haven’t found anything that works well that is electronic. Also, I’ve accumulated a number of notebooks from various manufacturers which I can use for my various works. Making it easy to capture is the reason that I have abandoned using most GTD systems, because they either require a lot of work putting things in order. This reason was also why I stopped using a system which I brought up with myself which was project-based, but would require me to update the correct card every time.
In the last few years, I’ve been using a set of systems which I read about from Mark Forster. I started working based on AutoFocus shortly after I discovered it. I was happy with the fact that the way to capture tasks in the system is just to open it to the last page and write down the task on it. With a marker for the last open page, it is basically the perfect ubiquitous capture - always available and no thinking required. I also like it because I don’t have to do the tasks in any particular order. One of the problems that I was having with the GTD system was the order of contexts, where I had to sort everything into different zones. It was very easy to go overboard, especially because I have at least three contexts which are mentally separate, but in the same physical location. It’s the nature of working on a thesis, running a consulting company and doing housework in the same place. AutoFocus was the first system where I could just take a look at a number of tasks, and do the one that I feel like working on at the time, which is a good thing for whatever context that I’m on.
Since then, Forster has revised his system four times, and then made a major change to it, adding a urgent list in the SuperFocus system. This is the system that I’m using now at work. It works fairly well and I’m thinking of working it into my personal system sometime soon. The urgent column works very well for items that need to get done right away. It seems like not many people know about these systems and they’re working okay for me so far. It’s easy to pick out something that needs doing that I can do right away, add a new task whenever I need to, and also to remove tasks which I will never do. One of my only complaints is that it’s a little hard to understand from scratch, even though it only uses one notebook. Maybe I’ll post an example of the working soon.


Today I went to MinneBar 6, which seems like it was the most populated one I’ve ever been to. It wasn’t as crowded as the first one that I attended, which was in a much smaller space with less people. This year went off pretty much without a hitch as an attendee. I attended some good talks with some great discussion.
At the start of the day Garrick van Buren gathered a bunch of people in a room and we talked about the Do Not Track thought space. I haven’t really been paying that much attention to the area, but it’s getting more and more nefarious from the tracking side it seems like. Mykl Roventine brought up at the end a whole new tangled ball that I hadn’t thought about in the form of affiliate programs - where sites are giving your purchase information to all of it’s affiliate partners in order to have them flag the items that they are responsible for. They’ll probably both be interested in the fact that I am running awstats for my own server, and I was previously going to re-add Google Analytics but have decided against it. The server logs are all I really need, at least for this site. There is an interesting trade-off here though, because many users will bring traffic to your site by putting on Facebook’s Like button or the Tweet This button, and the advantage of the extra traffic should be considered.
Next there was a good session about getting started with Android, that was in the largest room, which to me seems the least “MinneBar”-ish - the smaller rooms make discussion and question asking a lot easier. Donn Felker of QONQR did a great job of making the room work though, asking for topics before he started and handling most of them. It was not a lot of coding but a lot of focus on tooling as well as the details about monetizing your idea. One thing that I took away from this session was that people should start with the minimum viable product. If it’s going to be paid, start it out cheap and people will buy it anyway if they think it’s useful. I should have asked about what the change from a 24 hour to a 15 minute refund policy has had on sales of paid apps, especially on the small functionality MVPs.
I didn’t see anything all that interesting for the third session, so I fixed a couple of bugs and handled some emails, and talked to Garrick for a couple minutes while the directly before lunch. Grabbing some pizza, I talked to some students from St. Cloud who are just finishing up, and then walk around looking for some other people to talk to. John Chilton found me and we chatted a bit. I’m rubbish at networking at MinneBar. I don’t feel like I can sit down at a table that already has a group of guys at it and make connections - it could be that I’m just not great at it, or something about the tables or that there is always wifi available. I see a lot of guys from my twitter followers but I don’t tend to actually chat with them.
In the afternoon, Charles Nutter won the award for the most technical presentation of the day, going over almost all of the JVM bytecode operands while going over a short explanation of the stack machine that it runs on while encouraging everyone to learn a little bit about the bytecode that so many of our programs compile down to. A completely full room really indicated to me that there was untapped audience at MinneBar this year who would have accepted some more technical sessions.
Directly after that, the most entertaining session went to Charles again, this time assisted by his son, with an ad-hoc session about Minecraft. I’m a big fan of the game, but I haven’t played it in a while so I saw some of the new features, and had a good time chatting with some other gamers in the crowd. That’s also another audience that I think could be approached at the next MinneBar - something for the leisure time.
In the remaining sessions, I attended one on gathering your data about your users and plotting it in a useful way, mining the data that you already have in order to get good analytics. This was somewhat technical but quite cool because they sliced and diced the creative commons StackExchange Data Dump to show some interesting things. I seriously consider implementing some of these for my consulting work, they seem like the kinds of data that would be very appreciated to show growth to investors and the like. The last one I went to was more of a discussion about how designers and coders should cross-pollinate a bit when they are learning. Designers should learn a bit of code, coders should at least know a little bit of Photoshop / Fireworks… at least enough to get the job done.
I was pretty tired at the end of the day, so I didn’t stick around for much of the beer, also I was driving home and actually had to get some stuff done in the evening. I also just wasn’t feeling up to the networking aspect just then, partially discouraged because of my earlier failure to get into it around lunch time.
Overall, I would say that MinneBar 6 turned out to be a great BarCamp, with some wonderful sessions. The ones that I attended were all worthwhile. I didn’t “vote with my feet” and switch sessions in the middle of any this year - if I remember correctly I think I actually did that last time. I came across with a couple of thoughts - I’d really like to do a presentation next year about something. I feel like I should be able to contribute something to a conference like this, especially because there is such a wide range of topics presented on. Also, I feel a lot more comfortable getting my networking on in a smaller, more focused group - something like Ruby Users of Minnesota meetings, where I know that any person there is going to have more in common with me than one of a thousand. I’ll look forward to going to this next year if I don’t have a conflict though, and I encourage the same to anyone else in the tech community in the Twin Cities.