Doing the Easy Hard Thing
I’ve written recently about Health Month and the fact that I am trying to do things on a more habit basis. Last month I had a twelve rules, more than in March and a lot of things to track whether I was doing every day. At the same time, I wasn’t getting the important things done. Two of my rules were consistently not getting done. The rules were of course the most important ones - “Make progress on the thesis” and “Read papers for my thesis”. These are very likely the most important things that I need to get done, and they were getting drowned out by insignificant rules like “Floss every day” and “Only drink 4 cups of coffee a week”.
This month I’ve decided that my rules are doing to only be the important things that need to change and are actually difficult. This might mean that I have less of incentive to get the small things done which will be a good improvement, but I don’t think so - I’ve been doing those things for two months already and I don’t think I will be dropping them any time soon. With this in mind, the rules that I’ve chosen for May are more difficult, but also fewer:
- Do thesis work 5 days a week
- Read an academic paper 5 days a week
- Stay under my calories every day
- Write blog posts 4 days a week
- Exercise 40 minutes 5 days a week
- Go to bed before 10pm 5 days a week
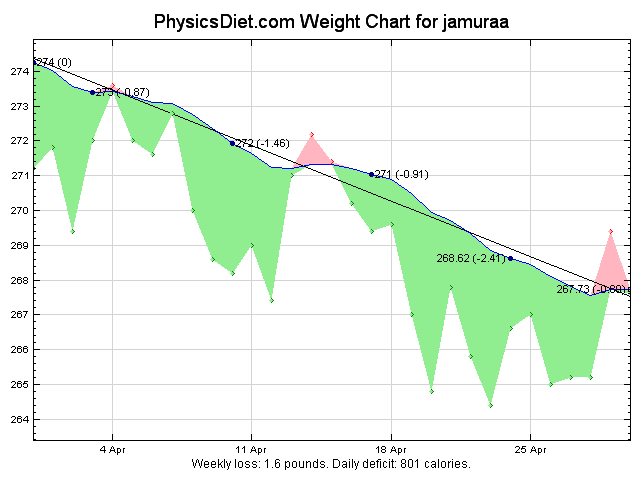
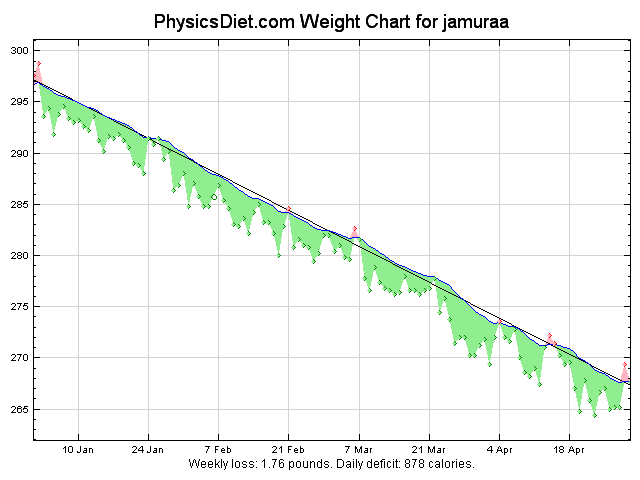
The “gimmie” rules on this list are still pretty hard, but they are the easy hard things. Exercising 40 minutes a day is easy for me, since I’ve been doing it a long time, but it’s still hard to get myself down to the room every time. It’s the easy hard thing - the thing that impacts my day enough that I don’t want to do it all the time, but once it’s started, it’s going to get done. Losing weight is hard. Almost anyone who has tried, successful or not, will tell you so. It’s also easy though, because the steps to complete it are straightforward - exercise and eat less calories. Most of my rules have been the easy hard thing in the last few months.
Blogging is the third easy hard thing on the list. It’s trivial to write blog posts once I make the decision to get it done, but it’s still difficult to wedge it into my schedule for some reason. For me, calorie restriction is also easy hard.
Going to bed is an example of another easy hard thing, but unlike the other two ones, I’m not getting it done. It’s extremely difficult for me to go to bed so early, even though I’m waking up earlier I still tend to be awake until at least midnight. Normally I would expect myself to have a hard time waking up early when I do that, but it seems like I don’t have that problem.
Unfortunately, the easy hard things aren’t the most important things. The rest of the rules are the hard hard things, that I have difficulty getting myself to do. They are the ones that I am really sad about not finishing, and the reason that I cut the insignificant rules this month. Now to actually get some of them done.